Linear time evaluation of Matérn 3/2 GP density in Stan using the SDE representation (NB: See the correction!)
CORRECTION 2017-06-03: The gradient evaluation here has quadratic time complexity as explained here.
Summary: Technical stuff about speeding up Bayesian inference performed with Stan, for a model with a one-dimensional latent process modeled by a Matérn 3/2 Gaussian process and a non-Gaussian likelihood (here, Poisson). The idea is that the contribution of the GP to the target density may be evaluated in linear time (w.r.t the number of observations) as opposed to the cubic time complexity of the approach based on inverting covariance matrices. (Caveat: I do not know what Stan's automatic differentation does but I expect that the time complexities are the same for the gradients. Let me know if this is false). The idea here is somewhat similar to the previous post, with the difference that this time the 'speedup' does not involve marginalizing any variables out. Instead, it only helps with a faster evaluation of exactly the same log-density (ignoring different floating-point errors). The speedup is demonstrated in an experiment, but seems to be only proportional to the number of input points (rather than to the square as one would expect based on the asymptotic complexities of only evaluating the GP density). Complete Stan codes are in an accompanying GitHub repository.
Contents
- 1 Acknowledgments
- 2 Introduction
- 3 Model definition
- 4 Converting the GP into a discrete-time dynamic system
- 5 Using the dynamic system formulation in Stan density evaluation
- 6 Possible reparametrizations
- 7 Experiment
- 8 Remarks
- 9 References
- 10 Appendix: notes about computing the discrete version of the dynamic system
1 Acknowledgments
The work documented in this post is a sidetrack of my PoDoCo project, which is funded by the Finnish Cultural Foundation and during which I have been a visitor at Aalto University, School of Electrical Engineering, Department of Electrical Engineering and Automation. Thanks!
2 Introduction
The work documented in this post is applicable to Stan models that contain a Gaussian process (GP) with one-dimensional input and a Matérn 3/2 covariance function, assuming that the GP cannot be integrated out in closed form due to, for example, a non-Gaussian observation model. The idea is that, while in general evaluating the contribution of the GP to the target density has cubic time complexity (in the number of input points), with certain covariance functions it is possible to evaluate the density in linear time. This is based on using an exactly equivalent representation of the GP as a linear dynamic system with a fixed-dimensional state (a linear stochastic differential equation, SDE). The SDE representation then enables evaluation of the density sequentially with fixed time cost per input point, thus in linear time. I do not provide a literature survey nor otherwise appropriate references here. Instead, see [1] for a general introduction to Gaussian processes regarding their use as a prior over functions in stats/machine learning and Arno Solin's doctoral thesis [2] for an overview of the GP/SDE connection. See both of these for references to original sources.
In this post, I consider a specific model with Poisson likelihood and certain priors on the parameters of the GP, but these parts are easily changed by changing the relevant lines of Stan code. The observation times (input points of the GP) are assumed to be equispaced but it should be rather straightforward to change this, although with more work than changing the aforementioned other model components. The Matérn 3/2 component is fixed however, in that while SDE representations exist for some other covariance functions (such as Matérn \(p+1/2,~p\in\mathbb{N}\)), finding the relevant analytic expressions and implementing them in Stan would require more work.
Section Model definition defines the example model used in this post, Section Converting the GP into a discrete-time dynamic system explains how to represent the Matérn 3/2 GP as a discrete-time linear dynamic system and Section Using the dynamic system formulation in Stan density evaluation explains how this is used for target density evaluation in Stan. I also tried two reparametrizations of the model, explained in Section Possible reparametrizations. Numeric experiments with results are in Section Experiment. Finally, there is the Section Remarks.
3 Model definition
Consider an observed sequence of counts, \(y_{1:T}\), which is are modeled as independent Poisson-distributed variables conditional on the value of a latent intensity process at the times of the observations. The logarithm of the latent intensity process is assumed follow a Gaussian process with Matérn 3/2 covariance function. The mean level of the GP is given an improper uniform prior, and the hyperparameters of the covariance function are given Student-t priors. The conditional independence structure is such that the joint probability distribution factorizes as
where \(x_{1:T}\) is the log-intensity process and \(\mu\) is the long-term mean, \(l\) the lengthscale and \(\sigma\) the standard deviation of the process. The relevant conditional distributions are
and \(l\) and \(\sigma\) are given half-Student-t priors with mode 0 and 2 degrees of freedom. For the time instances \(t_1,\ldots,t_T\), I assume the observations come at fixed intervals, so that \(|(t_j-t_i)| = |(j-i)|\,\tau\).
An 'as is' Stan implementation of this model is found in Matern32Poisson_basicGP.stan.
4 Converting the GP into a discrete-time dynamic system
Background in [2] and references therein, I just apply the results. For a practice-oriented introduction to stochastic differential equations, see [3]. We use the following notation for linear time-invariant stochastic differential equations (with states in \(\mathbb{R}^n\) for some finite \(n\)) in Itô form:
where \(\mathbf{x}(t)\) is the \(n\)-dimensional state and \(\mathbf{w}(t)\) is \(m\)-dimensional Brownian motion, \(\mathbf{F}\) and \(\mathbf{L}\) are constant matrices. [2, p. 27] specifies an SDE representation for a (zero-mean) Matérn 3/2 process as follows. The state is 2-dimensional (first component is the process-of-interest, the second component is its time derivative). The parameters are
and the stationary covariance is
where \(\lambda=\sqrt{3}/l\). The Brownian motion is scaled so that its variance per unit time step is \(4\,\lambda^3\,\sigma^2\).
The usefulness of the GP/SDE connection stems from the fact that from the continuous-time SDE we get an exact discrete-time representation as a dynamic system (for input points \(\mathbf{x}_1,\mathbf{x}_2,\ldots\), of the form
where \(\mathbf{A}_k,\mathbf{Q}_k\) depend on the length of the time interval between the inputs \(x_k,x_{k-1}\). This then enables using the Kalman filter and related algorithms for sequential inference.
For the purposes of this post, we need \(\mathbf{A}_k,\mathbf{Q}_k\) in closed form (as a function of the parameters). I did not find the matrices of the discrete-time system in closed form from my sources, so I'll describe their derivation in the Appendix. The end result is
where \(\tau\) is the length of the interval. Note that this representation is for a zero-mean process, to account for the mean level parameter \(\mu\), the system described in this section is interpreted to be the actual process translated to have zero mean.
5 Using the dynamic system formulation in Stan density evaluation
This is the main idea of the post: sequential evaluation of the conditional density \(p(x_{1:T} \mid \sigma^2,l)\) using the decomposition
To simplify notation, the dependence on the parameters is left implicit in the remainder of this section. Using the 2-dimensional discrete-time linear dynamic system from the previous section, all information in \(x_{1:k-1}\) relevant to predicting \(x_k\) is contained in \(x_{k-1}\) and the conditional distribution of the derivative,
which is known to be Gaussian due to the linear-Gaussian form of the system. The sequential evaluation of the likelihood may then be carried out by iterating the following steps:
- Compute the moments of \(p(x_k \mid x_{1:k-1}) = \mathrm{N}(x_k\mid m_k,P_k)\) as a function of \(x_{k-1},\dot{m}_{k-1}, \dot{P}_{k-1}\).
- Increment the log-density by log of \(\mathrm{N}(x_k\mid m_k,P_k)\).
- Compute the moments \(\dot{m}_{k},\dot{P}_{k}\) as a function of \(x_k,\dot{m}_{k-1},\dot{P}_{k-1}\).
This is essentially a Kalman filter when thinking of \(x\) as a measurement and \(\dot{x}\) as a state, except that the measurement depends also on the previous measurement, and I have combined the prediction and update of the state in step 3. The first step \(k=1\) is handled based on the stationary distribution of the process.
5.1 Computing the 'predicted' moments of the process (Step 1)
Here we assume \(p(\dot{x}_{k-1} \mid x_{1:k-1}) := \mathrm{N}(\dot{x}_{k-1} \mid \dot{m}_{k-1}, \dot{P}_{k-1})\) and aim to find \(p(x_k \mid x_{1:k-1})\). Use the decomposition
for the first factor apply the Markovianity of the 2D linear dynamic system and for the second factor the assumed form, to obtain
The conditional distribution of \(x_k\) is
Averaging over \(\mathrm{N}(\dot{x}_{k-1} \mid \dot{m}_{k-1}, \dot{P}_{k-1})\) we thus get
where
5.2 Computing the 'updated' moments of the derivative (Step 3)
The aim is to compute \(p(\dot{x}_k \mid x_k, x_{1:k-1})\). First, note that
and then apply the known form of the conditional distributions of the multivariate Gaussian to get
where
5.3 Stan code
Translating the equations above into Stan code, the 'filtering' (density evaluation) loop is
lda = sqrt(3) / lscale;
A[1,1] = (1+dt*lda)*exp(-dt*lda);
A[1,2] = dt*exp(-dt*lda);
A[2,1] = -dt*lda*lda*exp(-dt*lda);
A[2,2] = (1-dt*lda)*exp(-dt*lda);
Q[1] = stdev*stdev * (1 - exp(-2*dt*lda) * ((1+dt*lda)*(1+dt*lda) + dt*lda*dt*lda));
Q[2] = stdev*stdev * (lda*lda - exp(-2*dt*lda)*(lda*lda*(1-dt*lda)*(1-dt*lda) + dt*dt*lda*lda*lda*lda));
covQ = 2 * stdev*stdev * dt * dt * lda * lda * lda * exp(-2*dt*lda);
x[1] ~ normal(mu, stdev);
m_deriv = 0;
P_deriv = pow(stdev*lda,2);
for (n in 2:N) {
m = mu + A[1,1]*(x[n-1]-mu)+ A[1,2] * m_deriv;
P = Q[1] + A[1,2] * A[1,2] * P_deriv;
x[n] ~ normal(m, sqrt(P));
cov = covQ + A[1,2]*A[2,2]*P_deriv;
m_deriv = A[2,1]*(x[n-1]-mu) + A[2,2]*m_deriv + (cov/P) * (x[n]-m);
P_deriv = A[2,2]*A[2,2]*P_deriv + Q[2] - cov*cov/P;
}
Note that there are probably various optimizations available both in terms of minimizing evaluation time and minimizing floating-point arithmetic errors (also in the gradient evaluation) -- I have not put any effort into these considerations. Full Stan implementation of the model using this density evaluation loop is in the file Matern32Poisson_SDE.stan.
6 Possible reparametrizations
I have heard that reparametrizations sometimes help in Stan, for example, Section 17 of the Stan manual v2.11.0. Without any theory for why these would improve anything, I also try two reparametrized versions here. Both are based on introducing a vector that is a priori standard normal, and then constructing the signal by transforming this vector.
- For the basic GP version, the actual process is constructed by the affine transformation of the standard normal based on the Cholesky decomposition of the covariance matrix. See the file Matern32Poisson_basicGP_reparametrization.stan.
- For the sequential version, the process is constructed during the filter loop, that is, instead of the log-density increment, \(x_k\) is constructed by letting \(x_k = m_k + \sqrt{P_k}\,\hat{x}_k\), where \(\hat{x}_k\) is the standard normal parameter. See the file Matern32Poisson_SDE_reparametrization.stan.
7 Experiment
I simulated data from the model and performed inference with all 4 Stan implementations (basic GP, the SDE version, the reparametrizations). First, on a smaller dataset (5 points) so that a long run can be used to try to verify that the implementations indeed target the same posterior distribution and then with more data (100 input points) to highlight the efficiency of the linear-time version. The final subsection of this section provides notes about numeric errors causing the chains to diverge while in theory the target density is the same.
Note on the computing environment: the computations were performed on my laptop running Windows 10, and I have, for example, no idea what background processes were eating resources from the samplers and when. Please test on a more controlled/professional setup.
7.1 Data simulation
I simulated a time-series of \(T=100\) counts, with the intensity sampled from the model with parameters \(\mu=3,\sigma=1,l=0.2\) and length of timestep \(\tau=0.01\). The smaller dataset was then constructed by taking every 20th point from the full data (and correspondingly setting \(\tau=0.2\)). See the file generatedata.py.
7.2 Results with thinned data
All 4 samplers were run with 20,000 warmup steps and 2,000,000 samples (see the repository for full replication instructions). Selected parts of the summaries:
Inference for Stan model: Matern32Poisson_basicGP_model
1 chains: each with iter=(2000000); warmup=(0); thin=(1); 2000000 iterations saved.
Warmup took (16) seconds, 16 seconds total
Sampling took (1946) seconds, 32 minutes total
Mean MCSE StdDev 5% 50% 95% N_Eff N_Eff/s R_hat
lp__ 9.5e+001 3.2e-003 2.2e+000 91 95 98 4.8e+005 2.5e+002 1.0
mu 1.9e+000 3.5e-003 1.6e+000 -0.19 2.0 3.8 2.1e+005 1.1e+002 1.0
lscale 2.5e-001 5.8e-004 2.8e-001 0.018 0.18 0.72 2.2e+005 1.1e+002 1.00
stdev 1.8e+000 2.5e-003 1.3e+000 0.73 1.5 3.8 2.6e+005 1.3e+002 1.0
x[3] 8.1e-001 8.6e-004 7.8e-001 -0.59 0.90 1.9 8.3e+005 4.3e+002 1.0
Inference for Stan model: Matern32Poisson_SDE_model
1 chains: each with iter=(2000000); warmup=(0); thin=(1); 2000000 iterations saved.
Warmup took (14) seconds, 14 seconds total
Sampling took (1811) seconds, 30 minutes total
Mean MCSE StdDev 5% 50% 95% N_Eff N_Eff/s R_hat
lp__ 9.5e+001 3.3e-003 2.2e+000 91 95 98 4.6e+005 2.5e+002 1.0
mu 1.9e+000 3.7e-003 1.6e+000 -0.20 2.0 3.8 1.8e+005 1.0e+002 1.0
lscale 2.5e-001 6.0e-004 2.7e-001 0.018 0.18 0.72 2.0e+005 1.1e+002 1.0
stdev 1.8e+000 2.6e-003 1.3e+000 0.73 1.5 3.8 2.4e+005 1.3e+002 1.0
x[3] 8.1e-001 8.8e-004 7.8e-001 -0.58 0.90 1.9 7.8e+005 4.3e+002 1.0
Inference for Stan model: Matern32Poisson_basicGP_reparametrized_model
1 chains: each with iter=(2000000); warmup=(0); thin=(1); 2000000 iterations saved.
Warmup took (30) seconds, 30 seconds total
Sampling took (2886) seconds, 48 minutes total
Mean MCSE StdDev 5% 50% 95% N_Eff N_Eff/s R_hat
mu 1.8 2.0e-001 2.0e+000 -9.9e-001 1.9e+000 4.0 101 3.5e-002 1.0
lscale 0.28 1.5e-002 3.1e-001 1.9e-002 1.9e-001 0.86 416 1.4e-001 1.0
stdev 1.9 1.0e-001 1.4e+000 7.4e-001 1.5e+000 4.7 212 7.3e-002 1.0
x[3] 0.81 5.5e-003 7.9e-001 -6.1e-001 8.9e-001 1.9 20673 7.2e+000 1.0
Inference for Stan model: Matern32Poisson_SDE_reparametrized_model
1 chains: each with iter=(2000000); warmup=(0); thin=(1); 2000000 iterations saved.
Warmup took (26) seconds, 26 seconds total
Sampling took (3629) seconds, 1.0 hours total
Mean MCSE StdDev 5% 50% 95% N_Eff N_Eff/s R_hat
mu 2.0e+000 2.2e-002 1.3e+000 -5.3e-002 2.0e+000 3.9e+000 3.3e+003 9.0e-001 1.0
lscale 2.5e-001 4.4e-003 2.7e-001 1.8e-002 1.8e-001 7.1e-001 3.7e+003 1.0e+000 1.0
stdev 1.8e+000 3.9e-002 1.2e+000 7.3e-001 1.4e+000 3.7e+000 1.0e+003 2.8e-001 1.0
x[3] 8.0e-001 1.9e-003 7.9e-001 -6.1e-001 8.9e-001 1.9e+000 1.8e+005 4.9e+001 1.0
Results are close, so it seems believable that these target the same posterior. The linear-time-evaluation does not help with only 5 datapoints and the reparametrizations seem harmful.
7.3 Results with full data
All 4 samplers were run with 1,000 warmup steps and 1,000 samples (see the repository for full replication instructions). Selected parts of the summaries:
Inference for Stan model: Matern32Poisson_basicGP_model
1 chains: each with iter=(1000); warmup=(0); thin=(1); 1000 iterations saved.
Warmup took (2458) seconds, 41 minutes total
Sampling took (1827) seconds, 30 minutes total
Mean MCSE StdDev 5% 50% 95% N_Eff N_Eff/s R_hat
mu 2.3 3.6e-002 7.9e-001 1.2 2.2 3.4 491 2.7e-001 1.0e+000
lscale 0.17 1.5e-002 1.0e-001 0.081 0.15 0.31 48 2.6e-002 1.0e+000
stdev 1.2 6.4e-002 7.9e-001 0.62 1.0 2.2 154 8.4e-002 1.0e+000
x[50] 0.97 8.4e-003 2.3e-001 0.57 0.99 1.3 715 3.9e-001 1.0e+000
Inference for Stan model: Matern32Poisson_SDE_model
1 chains: each with iter=(1000); warmup=(0); thin=(1); 1000 iterations saved.
Warmup took (127) seconds, 2.1 minutes total
Sampling took (105) seconds, 1.7 minutes total
Mean MCSE StdDev 5% 50% 95% N_Eff N_Eff/s R_hat
mu 2.4 4.0e-002 1.0e+000 1.1 2.3 4.1 637 6.1e+000 1.0e+000
lscale 0.22 9.0e-003 9.4e-002 0.11 0.20 0.40 110 1.1e+000 1.0e+000
stdev 1.4 4.8e-002 7.8e-001 0.64 1.1 2.9 258 2.5e+000 1.0e+000
x[50] 0.99 7.2e-003 2.0e-001 0.66 1.0 1.3 741 7.1e+000 1.0e+000
Inference for Stan model: Matern32Poisson_basicGP_reparametrized_model
1 chains: each with iter=(1000); warmup=(0); thin=(1); 1000 iterations saved.
Warmup took (1240) seconds, 21 minutes total
Sampling took (1091) seconds, 18 minutes total
Mean MCSE StdDev 5% 50% 95% N_Eff N_Eff/s R_hat
mu 2.3e+000 8.7e-002 7.9e-001 9.4e-001 2.3e+000 3.7 82 7.5e-002 1.0e+000
lscale 2.1e-001 1.7e-002 1.0e-001 9.2e-002 1.8e-001 0.46 40 3.6e-002 1.0e+000
stdev 1.3e+000 9.5e-002 6.3e-001 6.4e-001 1.1e+000 2.8 43 4.0e-002 1.0e+000
x[50] 9.7e-001 6.7e-003 2.1e-001 6.1e-001 9.7e-001 1.3 1000 9.2e-001 1.0e+000
Inference for Stan model: Matern32Poisson_SDE_reparametrized_model
1 chains: each with iter=(1000); warmup=(0); thin=(1); 1000 iterations saved.
Warmup took (64) seconds, 1.1 minutes total
Sampling took (56) seconds, 56 seconds total
Mean MCSE StdDev 5% 50% 95% N_Eff N_Eff/s R_hat
mu 2.3e+000 2.8e-002 6.2e-001 1.3e+000 2.2e+000 3.3e+000 492 8.8e+000 1.0e+000
lscale 1.7e-001 3.6e-003 6.8e-002 8.8e-002 1.6e-001 3.1e-001 351 6.3e+000 1.0e+000
stdev 1.1e+000 2.4e-002 4.2e-001 6.1e-001 1.0e+000 2.0e+000 308 5.5e+000 1.0e+000
x[50] 9.8e-001 6.4e-003 2.0e-001 6.5e-001 9.8e-001 1.3e+000 1000 1.8e+001 1.0e+000
With this 100-points-data the SDE versions are faster, although only approximately 20 times faster rather than 400 times faster as one might naively expect from the linear vs. cubic complexity (as the runtimes were similar with the small data). Either I missed something, or perhaps the sampling algorithm in Stan is itself quadratic in the number of parameters or something.
Also, with this long data the reparametrized version of the SDE performs better (in terms of N_eff/s) than the original version, though longer&multiple chains could be used to further compare these as running them is relatively fast -- here I used only as many steps as with the basic GP versions and the chain length was dictated by how much time I wanted to reserve to run the experiment.
7.4 Note about floating-point inaccuracies
Since the (nonreparametrized) basic-GP and SDE implementations are constructed to evaluate exactly the same log-density, one would expect exactly same results with both samplers (compiled and run with the same compiler and computer, initialized with the same random seed etc.). Based on the summaries, the results are close, but not exactly same. Either I have a bug, Stan somehow takes the computing time into account in the adaptations, or the difference is caused by different floating-point arithmetic errors introduced by the different log-density-evaluators. I believe the last one to be the correct explanation and provide some evidence here. I again ran the nonreparametrized sampler with the small dataset, this time 1000 steps warmup and 1000 steps sampling, and saved the warmup steps, too. See the figure below for a plot of the lp__ variable of both samplers (EDIT: I cut off first 10 steps to get a more readable scale, as the initialization is poor and the log-posterior thus increases strongly).
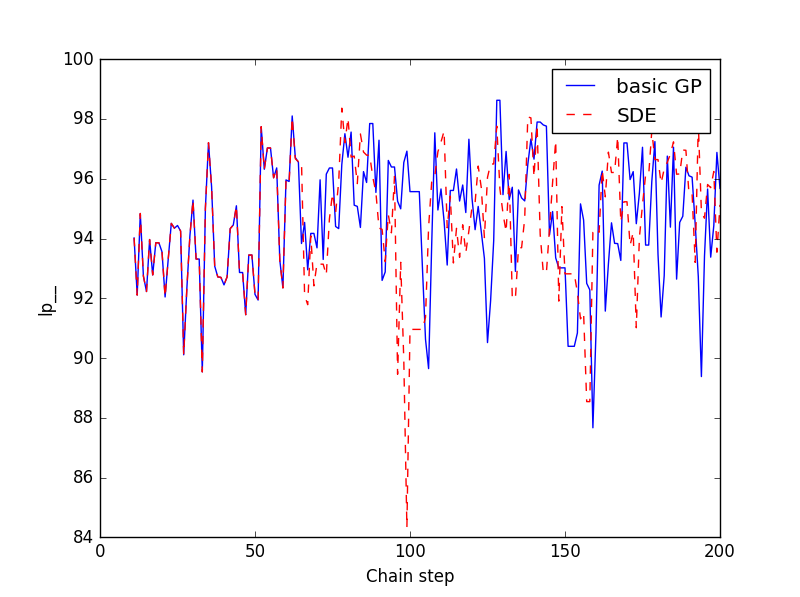
I conjecture what's going on is that initially small numeric errors cause only small differences between the samplers, but at one point the difference has an impact on some binary decision within the sampler, which causes the chains to diverge from each other. The paths becoming completely different does not however imply any instability in the sense that the samplers would not have within-epsilon-correct stationary distribution. However, I don't know what theoretical guarantees exist about MCMC behavior in the presence of numeric errors.
8 Remarks
- The SDE-based sequential version was considerably faster with the longer dataset, so I believe this approach is practically useful.
- I suppose faster evaluation and more readable Stan models would be attainable if the density (and gradient) evaluation were implemented in Stan itself.
- I wonder how worried one should be about the floating-point arithmetic errors -- I suspect that the sampler is in some sense stable so that they do not amplify into significant errors in the end results, but I do not know of any guarantees. One should test with the multiple chains (different random seeds) to see if the deviations are essentially an extra source of randomness or if the results of either of the samplers
- It is still of course possible I have bugs, no guarantees.
- I still wonder how to more efficiently test that two Stan models target the same distribution.
9 References
- C. E. Rasmussen and C. K. I. Williams (2006). Gaussian Processes for Machine Learning. The MIT Press. Online version.
- A. Solin (2016). Stochastic Differential Equation Methods for Spatio-Temporal Gaussian Process Regression. Doctoral dissertation, Aalto University. Helsinki, Finland. Online.
- S. Särkkä and A. Solin (2014). Applied Stochastic Differential Equations. Lecture notes of the course Becs-114.4202 Special Course in Computational Engineering II held in Autumn 2014. Booklet.
10 Appendix: notes about computing the discrete version of the dynamic system
Initially I used the matrix exponential's series definition and finding the results as sums of Taylor series of certain functions (also at one point using WolframAlpha for a hint), but the present version was easier to write up. For the mean of the system conditional on some initial state, we have the differential equation [3]
The first row of \(\mathbf{F}\) is just the definition of the second component as the derivative, so we may represent this a scalar second-order differential equation [4]
| [4] | Warning: I am boldly assuming that the mean of the derivative (i.e., the mean of the second component of the state) equals the derivative of the mean (of the first component). However, if we believe the background assumptions are correct, that is, the second component of the SDE representation is indeed the derivative (in some sense) and that \(d\mathbf{m}/dt = \mathbf{F}\mathbf{m}\) holds for this system, everything is fine without worrying about the mathematics behind. |
which is a second-order linear homogenous time-invariant differential equation familiar from any basic course on differential equations, solved by writing the characteristic equation
and since the polynomial has a double root at \(-\lambda\), the general solution is
with the derivative being
\(c_1\) and \(c_2\) are found by solving for initial conditions \(m(0)=m_0,~\dot{m}(0)=\dot{m}_0\), implying
whose solution is
and thus the solutions for the mean of the signal and of the derivative are
from which we can read the dependence on the initial state in matrix form
Since we have been given the stationary covariance \(\mathbf{P}_\infty\), we use an identity [2, p. 22]: